Architecture Document | Voice Verification for OnTrack Delivery
Introduction
Purpose
This document provides a comprehensive architectural overview of the Voice Verification system, using a few different architectural views to depict different aspects of the system. It is intended to capture and convey the significant architectural decisions which have been made on the system.
Scope
This Architecture Document provides an architectural overview of Voice Verification System. The Voice Verification System is being developed to address the issues concerning contract cheating on online learning management platforms.
Architectural Goals and Constraints
Goals
- Students can register their voice on OnTrack using the Speaker Verification system.
- Upon task submission, the attached voice file is analysed for verification.
- Deployed on the OnTrack instance in a docker container format.
- Support for gathering both front and backend telemetry should be present in the system to allow for analysis of user interaction, and system performance.
Constraints
- Speaker Verification system must have compatibility for voice recording across multiple browsers.
- Front-end components should comply with existing OnTrack requirements.
- System should adhere to existing OnTrack privacy/compliance requirements in addition to existing OnTrack security requirements.
Use-Case View
Architecturally Significant Use Cases
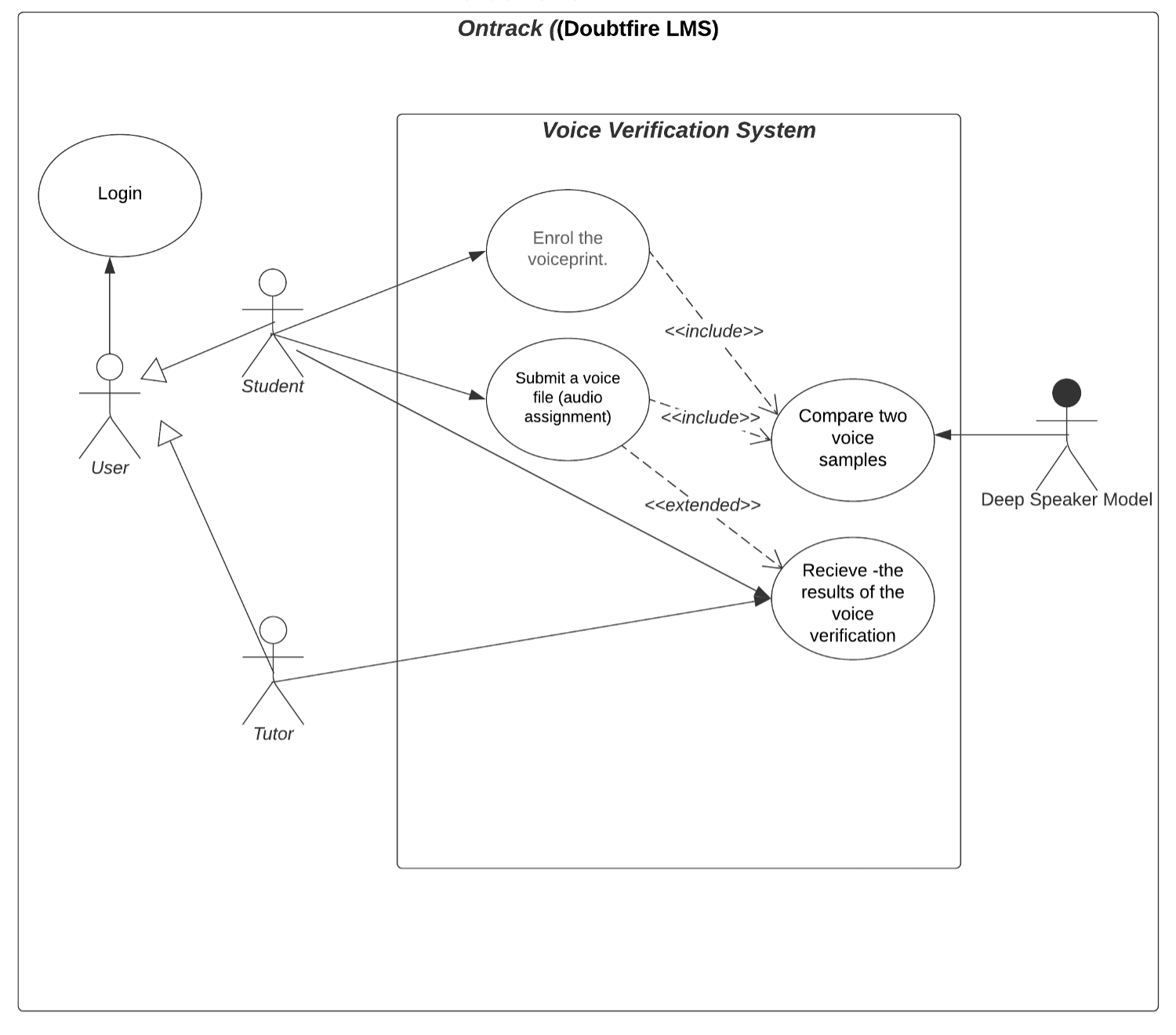
-
As a student, I want Ontrack to have a function that can identifies me by my voice. Description: The feature highlighted through this user story is having a “Enrol the voiceprint”. This feature allows a student to register a voiceprint for later verification
-
As a student submitting my assignments, I want able to upload audio files to Ontrack. Description: The feature highlighted through this user story is having a “Submit a voice file”. This feature allows a student to submit an assignment audio to Ontrack System.
-
As a Deep Speaker Classifier, “I” can recognise student by their voice at a confidence level. Description: The Deep Speaker Model is an actor involved within “Compare two audio samples” which will automatically confirm student’s identity by comparing their new voice submission to their voiceprint. This takes place within the Voice Verification Container.
-
As a tutor/student, I want to receive the result of voice verification to be aware of the outcome of the verification. Description: Voice Verification system will return/export the voice verification result to the Tutor and Student (a confidence score of how likely it is that the voice in the recording is the student in question) in a readable way.
Logical View
Architecture
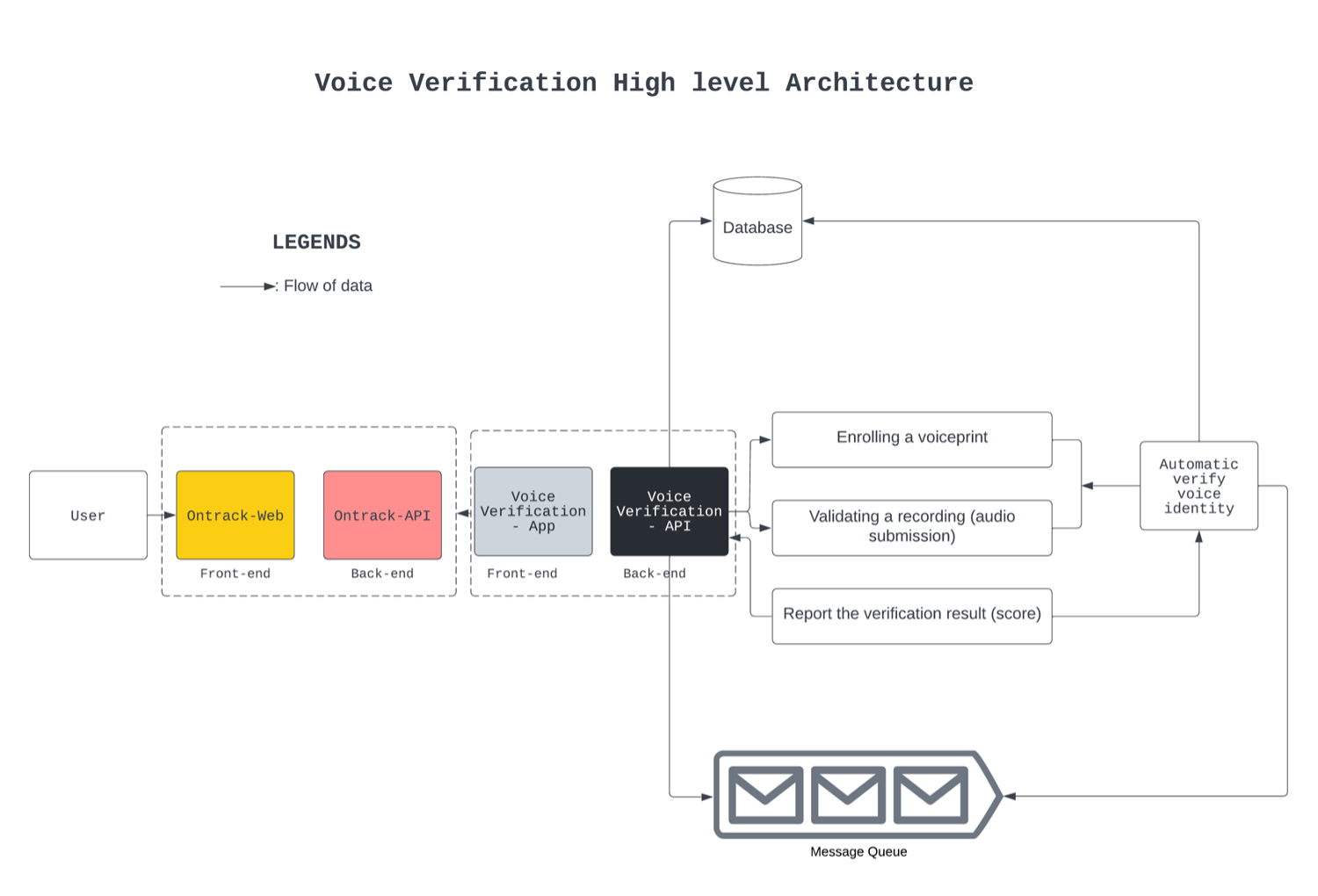
Detailed description of the architecture diagram
The diagram shows the communication types between each of the systems of the project. The User interacts with both the frontend website OnTrack and the voice verification system through a Ruby app. The voice verification method used takes advantage of Deep Speaker. Deep Speaker is a deep learning model that can be used to verify a user’s identity by comparing their voice to a voiceprint. The voice verification system is deployed in a docker container format.
General Flow diagram

The User has its requests go through the existing OnTrack system, with the OnTrack system sending further requests to the Voice Verification API. The sends the voice files to the docker container.
Size and Performance
The Size and Performance as of this stage cannot be calculated. However, the following information should be recorded when the system has been developed:
- Size of Voice Files for enrolment and verification.
- Response time for API calls
- Throughput of API calls
Quality
The Quality of the system must be further measured. The required information is as follows:
- Quality of Voice Validation results
- Testing of Voice Submissions (placing multiple speakers in the audio file, placing the speech at different stage of the audio file)